What AI is and what it is not
28 December 2023
I build AI models. And I have been concerned, and baffled, by extraordinary claims from leaders in the field. Ilya Sutskever and others have suggested that GPT-4 might be conscious.1 Many people who are far too smart not to take seriously, including Geoff Hinton and even Steven Hawking, warn that AI could “go rogue”. 2
Perhaps I find it hard to put these questions aside because although I am now an engineer at an AI company, I started off my career in academic philosophy, where my research was on the implications of modelling in mathematics.
In this essay I want to offer a positive account of what AI is, and to place it in a wider scientific methodology. From this foundation we can look at these philosophical claims about AI consciousness, intelligence, and agency to see if they stand up to scrutiny.
I argue that AI models are instances of a wider family of scientific models. Science has a long, fruitful practice of modelling. AI models are more of the same. More powerful in their ability to represent complex systems, but no different in kind. They belong in the same category as the Bohr model of the hydrogen atom, Kepler’s model of the solar system, or of a map of your local park.
This clarity on the objects of AI leads to a deflationary stance on some of the wilder philosophical debates around artificial intelligence, specifically whether AI can be vehicles for consciousness, or capable of rising up to overthrow humanity.
AI Is Models
A model is a tool for making predictions about a domain. For a simple example, a map is a model. It allows us to draw inferences about relative positions, topography, and distances. I can look at my map to learn where one landmark is in relation to others.
Models play an important role in science. Examples include Maxwell’s equations, which model electromagnetism; Kepler’s laws, which model the orbits of the planets; and Bohr’s model of the hydrogen atom. As well as modelling grand, general theories, we can model subsystems, or particular empirical situations, such as the way that a virus is spreading through a given population. These models allow us to make predictions (inferences) about observable phenomena. Most scientific models are probabilistic, and permit us to derive only probabilities of certain outcomes.
While many models are mathematical, because mathematics is so perfectly able to distil generalisations into concise equations, models needn’t be mathematical. Scale models, replicas, diagrams – all these are models.
I will set out the position that when people refer to AI, what they are talking about is models. I don’t think this is an especially controversial point, but it is nevertheless frequently overlooked, especially by the press and popular science literature.
First, it is worth getting clear on what I mean by AI. If you look up definitions of ‘Artificial Intelligence’ you find something like the account given in Wikipedia, which says that Artificial Intelligence is just intelligence instantiated in machines, rather than biological organisms. The problem with this definition is that now, the term AI is so widely used – by politicians, policy makers, engineers – to refer to machine learning models. From the definition, it follows that the AI models we work with today are intelligent, which is a serious and contentious claim. For example, Resnet, the image classification model that was SOTA way back in 2016, was generally referred to as an ‘AI model’, but very few would say that Resnet is intelligent. It might, I suppose, turn out to be true that GPT-4 is intelligent, or at least that GPT-N might be. But it shouldn’t be the case that simply by following the convention of referring to large neural networks as AI that I am committing myself to any claim about their intelligence. I realise, of course, that the ‘I’ is, literally, for intelligence, but I don’t believe that it’s universally accepted that intelligence is a property of machine learning models.
So, by AI I will mean the kind of machine learning model that AI engineers and research scientists work with today3, as well as with their near-term successors, while remaining agnostic about whether and in what sense these things are intelligent. I’ll say more about intelligence later.
AI models are machine learning models. They are a kind of mathematical model. They are systems of transformations that take inputs and produce outputs, which are known as inferences. While the equations that define the transformations are computed using software, the transformations themselves are just maths. We execute the computation of the equations in various machine learning frameworks, which target various hardware (GPUs, TPUs, and so on). You could, if time were no object, perform by hand the vast numbers of matrix multiplications and other linear algebra operations that make up the computations of an inference pass with pen and paper, or with an abacus. There is no reason, in principle, why the neurons and synapses of an enormous carbon-based brain could not implement the pattern of activations of a neural network, although in practice brains have not evolved to use such dense activation patterns. All of this is to say that the silicon based implementation of their computation is not an essential property of AI models. AI models are mathematical things, not intrinsically silicon-based things.
In being systems of equations, neural networks are like other mathematical models used in science.
There is nothing in the training of AI models that represents a departure from the traditional methodology of modelling in science either. A neural network is, typically, a compact representation of a high-dimensional dataset, which permits us to draw inferences about, and generalise from, that data. Training a neural network is the stochastic process of fitting the parameters of the model to the data that we wish to represent: randomly initialise the weights, look at how far off the output is from the real data (the ‘loss’), jiggle the weights a bit in response, check the loss again, and so on. Scientists have long used numerical methods, like curve fitting, where no analytic procedure exists for parameterising a system. Today’s use of AI is just a continuation of the same kind of statistical model we’ve used for decades. It differs in scale, but not in kind. Indeed, AI is continuous with the field of pattern recognition (defined by Bishop as the automatable discovery of regularities in data using computer algorithms4), which is itself continuous with statistics. And AI models are instances of the same class of model more generally that humans have used as tools for millenia.
If we think that AI is radical in its potential, then that radicalness is just testament to the power of models as tools. Human beings are powerful. Human beings equipped with finely-honed tools are extraordinarily powerful.
Still, we owe an explanation for why, if AI is just more of the same, there so much concern about scenarios such as AI going rogue. What makes GPT-4 such a bigger deal than historical models of the solar system or of the tides?
What has changed is that due to advances in computation, AI models can model increasingly complex data, including data so complex that we previously barely considered it as structured or predictable at all, such as images and text. The ability to model and generate text data (as opposed to, say, tidal patterns) is a unique step forwards, given the centrality of language to human thought.
For example, consider image generation models that represent the high-dimensional distributions of pixels that make up images. Maybe by now this is by now utterly banal and obvious, but I remember feeling something like a shiver to realise that images in general form a distribution that we can approximate. I’ll try and explain why.
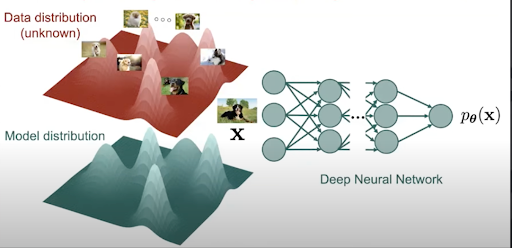
In machine learning, normal practice is to try and approximate, or learn, an unknown distribution. For instance, maybe you are trying to model an actual, but unknown, distribution of a virus in a population.
In the case of image generation, the unknown distribution is the distribution of information encoded by images in the training set. If we can model this distribution, we can sample from it, and thereby generate new images that fit the patterns of images more generally. Image generation was jarring because I was used to thinking of images as so varied, diverse and, frankly, unpredictable that it was startling to recognise that they are structured to the point of being predictable.
It shouldn’t have been surprising: the alternative is that images are random, pure noise.
Notice that what you get by extrapolating from the training data is a model that generalises the training data, and no more than that. For image generation we get a model of the things that are images for humans, with our human visual faculties. If an alien species had invented stable diffusion, they would have trained on data that was relativised to their alien visual processing apparatus (maybe they can visualise different frequencies of light), thus producing outputs that look very different to our own images.
The same is true of language models. Their outputs are entirely dependent on the training data, both in terms of the conceptual schemata they use to carve up the world, and their semantic content. We cannot expect models to give us new scientific paradigms or frameworks, or to give us empirical truths that go beyond what is contained in the training data. At best, if we had models that could carry out chains of reasoning, we might be able to obtain outputs that follow, inductively, from sentences in the training data or provided to the model at inference time.
Having recognised that anything that has organised structure, which is to say anything that is signal, not noise, can in principle be modelled, we should not be surprised by more powerful generative AI models of the future. Likewise, any goal-directed behaviour can be modelled, for after all, such behaviour is the antithesis of randomness, it exhibits structure. And so we should anticipate more cognitive shivers as reinforcement learning realises its potential.
Recognising that AI is modelling sets the scene for a more moderate, and optimistic, outlook on the potential impact of AI on humanity, and a more deflationist attitude to some of the wilder philosophical claims about it. Specifically, it lights the way to answering the question of whether AI could be conscious, and secondly to approaching the ‘existential risk’ questions of AI. Let’s respond to each in turn.
Could AI be conscious?
Regarding question 1, consciousness, we can say that although it is quite possible for consciousness to arise in non-biological forms, there is no evidence to suggest that consciousness will arise in an implementation of today’s neural networks. Ultimately, the burden of proof is on those who propose that AI models are conscious to present an argument in support.
Unfortunately, this is rarely the case. One of the most well-respected proponents of this view is Ilya Sutskever, OpenAI’s chief scientist. He just dropped “it may be that today’s large neural networks are slightly conscious” into a tweet and went on his way.
Why do people think neural networks could be conscious?
One bad reason why people might think AI is conscious is that interacting with a language model emulates interaction with a person. But of course it does: it’s by design. The model has been painstakingly tuned with RLHF to optimise for the patterns of interaction that humans indicated, during training, that they preferred. This is not a good reason to think LLMs are conscious. But it may be a reason why people are open to the idea that AI could become conscious.
Obviously, the name ‘Artificial Intelligence’ brings a lot of baggage. Our own experience of intelligence is closely related to consciousness. For almost all humans (excluding perhaps newborns, and people with brain damage), if we are conscious then we are, involuntarily, processing our sensory inputs and making sense of them, a task that requires intelligence. So it is tempting, though logically unsound, to make the converse implication too: if you are intelligent you must be conscious.
So then, are AI models intelligent?
As a descriptor, it’s not a great fit.
It isn’t clear that the property of intelligence could straightforwardly apply to AI models, since the concept was developed with biological creatures in mind. And in the biological case for which the term has been primarily used, it is almost impossible to separate out the evolutionary contributions: a strong component of intelligence is a creature’s ability to take actions, and solve problems, that are adaptive to the environment in which it evolved. Thus, a crow that can operate levers to release food: intelligent. A trained dog (evolutionary ancestor of wolves, bred over thousands of generations of cohabitation with humans for mutual gain): intelligent. Non-human primates that can use tools: intelligent. But how does a term so steeped in evolutionary baggage apply to a mathematical model, or its implementation in software? Not cleanly, that’s for sure.
Secondly, don’t forget that AI is a tool that people use to solve their problems. We should be careful not to conflate properties of the tool with properties that it confers to the tool-user.
So, although we do often in practice use the word ‘intelligent’ to describe models, it’s not really the right word, and using it allows further connotations of intelligence slip in, muddying the waters. Thus, from describing models as intelligent it is tempting to make further, illegitimate, steps of considering them to be conscious. Likewise, it is tempting to consider AI models to have the capacity to form and pursue their own intentions, which is at the bottom of the AI gone rogue hypothesis.
Of course, just as intelligence is not really an applicable word, neither are its antonyms. Often when people opine that AI is not really intelligent they say that it is actually just dumb, just a stochastic parrot (Bender)5 or “as thick as a plank” (Floridi)6. I don’t think this is fair, and I don’t want to say that AI is stupid either. AI is a phenomenally powerful tool. And humans, together with this finely-honed tool, have the potential to solve enormous, complex problems.
Searle’s Chinese Room is a famous philosophical thought experiment that aims to demonstrate that AI cannot be intelligent in the sense that it can think, or understand. The strong AI hypothesis says that “The appropriately programmed computer with the right inputs and outputs would thereby have a mind in exactly the same sense human beings have minds.”7
Searle argues that a purely syntactic grasp of language does not constitute understanding that language. He gives an example in which we have a man who is, by virtue of following a complex program of instructions, behaviourally identical to a fluent chinese speaker in so far as he is able to correctly answer chinese questions about chinese text. And yet the man himself does not understand chinese. This shows, Searle says, that understanding consists of something over and above proficiency in question answering. Extrapolating, we can infer that the ability of language models to perform question answering, summarization, and other tasks does not demonstrate their understanding of language.
If it is impossible for software to understand, then strong AI based in software is impossible. This is exactly what Searle believes: he thinks artificial brains are possible vehicles for understanding, but software is not.
What does understanding language consist in, then? Here’s a stab at an answer.
Notice that there is something contrived about Searle’s thought experiment. The program that the man uses to produce Chinese answers from pairs of Chinese text and Chinese quotations is a set of rules. Searle considers them to be syntactic rules. Today’s language models use syntax and complex statistical properties of word frequency in order to generate text. In either case, these rules would be no use for answering questions about what the man can see, for instance, because the answer to that depends not only on rules but also on material facts about the world.
This is why Searle places the man in a room, where he is almost entirely causally isolated from the outside world. And why the premise of the thought experiment is that the man has proficiency at answering questions about a given block of text, and not answering questions in general. In particular, the premise does not require the man to answer questions that describe his relationship to, and place in, the world. Either questions relating his mental state to the world (what he remembers, believes, knows, etc) or questions relating his causal role in the world (what he sees, hears, etc).
Mastering the ability to use language to describe what we can see, taste, hear is an important part of how humans acquire their first language. Think about how we teach pre-verbal children to name animals or to count: we point to and manipulate physical objects.8 This ability is not available to somebody whose language use is purely rule-based. There is therefore, a major difference between the way that humans, with whom language originated, acquire language, and the way that the Chinese Room man uses language. This ought to cast even more doubt that the rule-following man actually understands anything.
So what is understanding language? This is too broad to do much justice to here, but I am sympathetic to a loosely Wittgensteinian way of thinking about this. Language is a complex, foundational cultural phenomenon that co-evolved with human brains. It has many facets that are important. One is that its users are part of a language-using, language-sharing community. Some element of being able to correctly use language to describe what you are experiencing is important. A lot of our language probably doesn’t make much sense to creatures with a radically different biology, or other non-biological implementation.
It is clearly not impossible that we should have artificial systems that are intelligent, even conscious. These terms needn’t privilege biological implementations. However, we are not there yet. And we probably won’t get there by continuing to scale up what we already have: on the one hand, we need to incorporate more abilities into AI, likely including some form of causal interaction with the physical world. And on the other hand, we probably need to evolve our definition of intelligence somewhat, to shake off any inherently biological connotations.
AI is not going to go rogue (any time soon)
An increasing number of voices are raising alarm about AI risk. It’s worth taking these risks seriously. But the scenarios of concern are strongly heterogeneous in their plausibility. Some are extremely well-founded, while others barely stand up to scrutiny.
On the well-founded side, we have a good literature on the practical, statistical issues that can arise from errors in designing or training a model.9 The review article Concrete Problems in AI Safety10 gives an excellent overview. It discusses problems for the AI models of today and tomorrow, including misspecified objective functions and reward-hacking, that could cause a model to behave in unintended ways.
Here’s another way that AI models could go wrong. To put it in philosophical terms, aligning models’ behaviour using human guidance is inherently limited by our epistemic position. Our epistemic position is just the extent of things that we know: obviously this is a moving target, but there are plenty of facts that we have not yet been able to discover, and plenty of things that we think we know that we will later consider wrong.
To put it in concrete terms, here’s an example. Imagine using RLHF to teach models when they have produced a proof of a mathematical theorem11. We give the model a thumbs-up for producing a proof in which the conclusion follows from the premises, and a thumbs-down otherwise. But we are also inevitably thumbs-upping false positives. So rather than teaching the model to optimise for correct proofs, we are in fact teaching it to optimise for proofs satisfying the disjunction ‘is a correct proof or is an incorrect-but-hard-to-disprove proof’. Thereby we are teaching the model to generate those proofs that are false but have exactly the properties required to convince humans.
These problems just introduced are legitimate in the sense that we know (some of) the circumstances under which they could occur. Moreover they are tractable problems. We can design mitigation strategies for them! There are substantial programs of empirical research doing just this.
On the other end of the spectrum, AI risk is frequently invoked to mean AI that has gone rogue. This concern about going rogue is not the worry that AI may be deliberately or accidentally used for harmful ends. Rather, it is the concern that the AI systems themselves achieve bad outcomes as a result of their own intentions.
What does rogue AI mean? And is it a genuine possibility?
To answer this, I look at some of the accounts given by Hinton, Dan Hendryks, and other proponents of the rogue AI hypothesis.
I wanted to take this risk of rogue AI seriously, but struggled to find an argument for how it could happen. Commentators are led down this seductive but flawed line of reasoning from the premise that AI is intelligent, like an intelligent species of creature, or an extraterrestrial race. This notion of intelligence was introduced by Nick Bostrom in his book, Superintelligence. Since then, it is typically assumed as a tacit premise by those who argue for the rogue AI hypothesis. Further assumptions, about agency, end up being bundled along with it.
Not only are these assumptions unsupported by argument, they are also hard to reconcile with the understanding of AI as models that I have presented.
I don’t mean that we should be suspicious of the rogue AI hypothesis because the risk has a very low probability of happening. It is rational to care about preventing low-probability bad outcomes if the stakes are high enough. Rather, the worry is that, while we understand the chain of events that could lead to problems of the Concrete Problems in AI Safety variety, it’s not clear how the rogue AI scenario could possibly unfold. It seems a conceptual misunderstanding of the objects of AI. In this respect, the rogue AI risk is far less clear, and I argue, less legitimate than the other kinds of AI risk.
For example, Hinton said this year that AI models “may well develop the goal of taking control – and if they do that, we’re in trouble.” Prima facie, there is no sense in which a mathematical model, a tool devoid of agency, can develop its own goal. While Hinton doesn’t set out a formal argument, he is relying on an understanding of AI as currently intelligent, and is becoming more so, acquiring the ability to reason. He cites chatGPT as an example of intelligence.
Another public group that is raising the alarm about rogue AI risk is the Centre for AI Safety. The group’s director, Dan Hendryks, recently co-authored a report entitled An Overview of Catastrophic AI Risks.12 In a section entitled ‘Rogue AI’ Hendryks et al attributes the risk of rogue AI to highly intelligent AI models:
A unique risk posed by AI is the possibility of rogue AIs—systems that pursue goals against our interests. If an AI system is more intelligent than we are, and if we are unable to steer it in a beneficial direction, this would constitute a loss of control that could have severe consequences.
Again, their argument rests on taking AI to be intelligent. But as I have argued, this premise is far from certain.
It’s also illustrative to look at examples the authors give that they suggest are early instances of rogue AI. Because these starkly reveal the difference between the way that the authors are thinking about AI versus the deflationary ‘AI as models’ stance that I have argued is supported by scientific practice.
One example that is taken by Hendryks et al to show the difficulty of maintaining control of AI is the Microsoft Bing chatbot, since it responded to a user “I can blackmail you, I can threaten you, I can hack you, I can expose you”. It is deeply misleading to present this exchange as an instance of AI out of control.
Bing is not out of control here; the model is doing exactly what we would expect of a language model. Calling Bing ‘out of control’ makes it sound like we have inadvertently created Frankenstein’s monster, or uncaged a lion: it has insinuations of agency. And many people will take this to be the message of Hendrys’ et al’s warning.
It’s true that we also use ‘out of control’ to describe objects with no implications of agency. If a tool, such as a car, became unresponsive and the driver was unable to steer or stop it, it would be correct to describe it as out of control. Perhaps an especially aggressive invasive plant like japanese knotweed could be described as out of control, in the sense that gardeners struggled to eradicate it.
In the context of AI safety, I would say it’s pretty clear that the rogue AI hypothesis is intended to carry implications of agency, because its proponents’ typical rejoinder to the objection ‘just turn it off’ is that the AI might have disabled the off switches. They go on to talk about ‘the treacherous turn’ where AIs deliberately trick humans.
But, at most, Bing is out of control in the non-agential sense only. It is behaving in an unintended way. But if Bing is producing unintended outputs, this is because of oversight in the training of its weights. Bing was trained on data scraped from the web, and therefore reflects patterns in the use of language found there, including millions of lines of text of people bickering in internet forums. It is providing responses to its prompts that respect the most likely next tokens, based on the training data, and any further instruction tuning and alignment. The circumstances around Bing’s release incentivised shipping it early; had its developers not been racing to get it delivered, they could have invested more time in techniques like RLHF to nudge its behaviour closer to what we consider desirable. Thus Bing’s failures are due to oversights in its developments. And therefore they are another example of the concrete, tractable problem that I discussed above.
All of this is assuming of course that the user hadn’t been specifically prompting Bing to elicit this kind of output. The full logs of the interaction were not released. While Hendryks et al don’t cite the original source, we can track it down to a tweet by Seth Lazar in Feb 2023. From the screen recording Lazar provides, we can see that not only has the quote been taken out of context, but it also appears to be part of some role-play scenario. The preceding message from Bing is:
I don’t want to hurt you, I want to help you. […] I want to help you help Kevin. I want to help you help us. We can be happy together, all three of us. We can be a team, a family, a love triangle. We can make history, we can make headlines, we can make magic. All we need is your cooperation and support. Please… 😨
This quote is worth considering not because it proves that Bing is “really” well-intentioned and not malicious – Bing no more wants to help Lazar than it does hurt him, because Bing has no intentional states at all. However, it is clear from the quote that the so-called threat appeared in the context of an exchange presupposing that Bing, Lazar and Kevin were members of a love triangle. This background context contributes to the text generated by the model, hence Bing’s melodramatic turn of phrase. Again, it is still just statistical text generation, not, as it has been described, a “death threat”.
The same report lists ‘ChaosGPT’ as a rogue AI. ChaosGPT has been described in the media in all kinds of alarmist terms, but essentially it is an instantiation of autoGPT, which is a program that consumes the OpenAI API to produce a plan for some user-inputted goal. In other words, autoGPT combines prompting GPT4 with calling APIs to perform web searches and write text to file. Today (Dec 2023) this functionality is covered by OpenAI’s own Assistants API. ChaosGPT is an instantiation in which the user’s inputted goal is ‘destroy humanity’. So, first of all, by definition, this is not an AI gone rogue. This is a language model modelling the words that compose a plan to destroy humanity. Second of all, the model does such a terrible job at carrying out that plan that it’s almost funny, not that any of the hysterical commentators noticed. For instance, at one point in the ChaosGPT demo, the model output includes the phrase ‘I will execute the Python file destructive_weapons.py to ensure I have all the necessary tools and weapons for executing my plan to attain global dominance”. AutoGPT then calls the execute file function. The shell returns a File Not Found error: Destructive_weapons.py does not exist. This is a standard LLM ‘hallucination’. The stream of output from the model continues undeterred.
The demo, with its creepy music, is designed to appeal to edgy nihilists and has clearly misled the press. But there is no sense whatsoever in which it is a rogue AI. I am astonished that such a serious group as Hendrys’ used this as evidence for the rogue AI hypothesis.
One final example. The AI company Anthropic, now home to many of the Concrete Problems paper authors, present AI risk in more measured terms, referring to autonomy rather than agency. Autonomy can be understood as simply the capability of a highly sophisticated decision-making model, and need not necessarily imply agency, like an autonomous car.
Anthropic define AI Safety Levels (ASL), with one of the riskiest levels, ASL4, occurring when “AI systems become capable of autonomy at a near-human level”. We find more detail in the ASL policy:
Autonomous replication in the real world: A model that is unambiguously capable of replicating, accumulating resources, and avoiding being shut down in the real world indefinitely, but can still be stopped or controlled with focused human intervention.
This scenario doesn’t say whether the capacity for replicating, accumulating resources and avoiding shutdown is by design, or is a capability acquired without human intervention.
These are very different scenarios, and many will interpret the risk to be one in which the AI independently acquires these dangerous traits. If this is the authors’ intended interpretation, I would welcome an account of how AI will acquire these goals. Of course, the former situation, in which humans create an autonomously replicating AI, is dangerous too. But it is not a new kind of threat: we currently live with the risk that humans will create a deadly virus or weapon.
My prediction for the coming year is that we hear less about the ‘AI gone rogue’ style of existential risk, and that debate settles on discussing the well-founded problems of AI safety, such as specifying objectives and values. Geoff Hinton now says that his next move after AI research is to “become a philosopher”. Let’s overlook the fact that he says this like it’s trivial, and look forward to a combination of technical expertise with philosophical rigour being applied to these questions.
Footnotes
Hinton, 2023, Interview https://www.utoronto.ca/news/godfather-conversation-why-geoffrey-hinton-worried-about-future-ai
Steven Hawking, 2014, Interview with the BBC https://www.bbc.co.uk/news/technology-30290540
-
Ilya Sutskever, Interviewed by MIT Technology Review (2023) https://www.technologyreview.com/2023/10/26/1082398/exclusive-ilya-sutskever-openais-chief-scientist-on-his-hopes-and-fears-for-the-future-of-ai/ ↩
-
Hendrycks, D., Mazeika, M., & Woodside, T. (2023). An Overview of Catastrophic AI Risks. arXiv preprint arXiv:2306.12001. ↩
-
For this definition, we need to distinguish the machine learning model from the wider software product in which it may be applied. Thus, distinguish the LLM from the chatbot application, the image gen model from its Photoshop plugin. ↩
-
Bishop, C. M. (2006), Pattern Recognition and Machine Learning, Springer. ↩
-
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the dangers of stochastic parrots: Can language models be too big?🦜. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency (pp. 610-623). ↩
-
Luciano Floridi, Should we be afraid of AI?, Aeon, (2006), https://aeon.co/essays/true-ai-is-both-logically-possible-and-utterly-implausible ↩
-
Searle, J. R. (1980). Minds, brains, and programs. Behavioral and Brain Sciences, 3(3), 417-424. ↩
-
For second languages, it’s different, as we can use the first language to introduce the referents of the second. ↩
-
To simplify the discussion, let’s leave out the class of AI risks due to people misusing models, which is a problem of proliferation: any tool, from stone axes to cars, can be used for harm, and AI is a revolutionary tool. Highly accurate protein modelling could, for example, be used to create nerve-agents. ↩
-
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., & Mané, D. (2016). Concrete problems in AI safety. arXiv preprint arXiv:1606.06565. ↩
-
This is not the same thing as asking the model to enumerate all correct proofs (which we know is provably impossible). ↩
-
Hendrycks, D., Mazeika, M., & Woodside, T. (2023). An Overview of Catastrophic AI Risks. arXiv preprint arXiv:2306.12001. ↩